· Alvaro Barber · Tutorials · 4 min read
Data Vault with Snowflake
Hash Keys and Hash Diffs used for Data Vault

Data Vault is a modeling methodology and architecture designed for building highly scalable, flexible, and resilient data warehouses. The key principles and components of the Data Vault methodology include:
- Hub
- Links
- Satellites
All of the components use hash keys and hash diffs. They are techniques mostly used to handle the identification of changes in data records.
Why to use Hash Keys and Hash Diffs
Hash Keys:
Hash keys are cryptographic hash values generated from the attributes of a data record. These hash values serve as unique identifiers for the records. Purpose: Hash keys are used to uniquely identify records within the Data Vault. They provide a reliable and efficient way to detect changes in records by comparing the hash values of incoming data with those stored in the data warehouse.Hash Diffs:
Hash Diffs, short for hash differences, represent the changes between two versions of a data record. They are computed by comparing the hash values of the current and previous versions of the record. Purpose: Hash diffs are used to identify changes in the attributes of a data record over time. They provide a mechanism for tracking historical changes and determining the delta (differences) between successive versions of the record.
Go to the links below to watch the demonstration and run the example with the code provided in the github repository
Example
HASH KEY
Column that represents a unique identifier(new rows). The typical case would be creating a hashkey from ID column(primary_key).
SELECT CAST(SHA2_BINARY(ID) AS BINARY(40)) as HASH_KEY
HASH DIFF
Columns that track changes between same rows(records with the same hash key). Hash Diff normally involves creating a hash from more than one column. For this case, let’s create hasdiff from NAME and SURNAME
SELECT CAST(SHA2_BINARY(NAME ||'||'|| SURNAME AS BINARY(40)) as HASH_DIFF
EXAMPLE
Name: wetrustindata
Hash: c0a3d27f1fde81714a6c0dbf3b95e2c9e9936edf3debb15cf6ccf51c48d3b5a9
Golden Rule
The golden rule to remember and to take into account whenever changes needs to be tracked between two tables is:
DIFFERENT HASH KEYS - INSERT ROW
SAME HASH KEY BUT DIFFERENT HASH DIFF – UPDATE RECORD
SAME HASH KEY AND SAME HASH DIFF – DO NOTHING
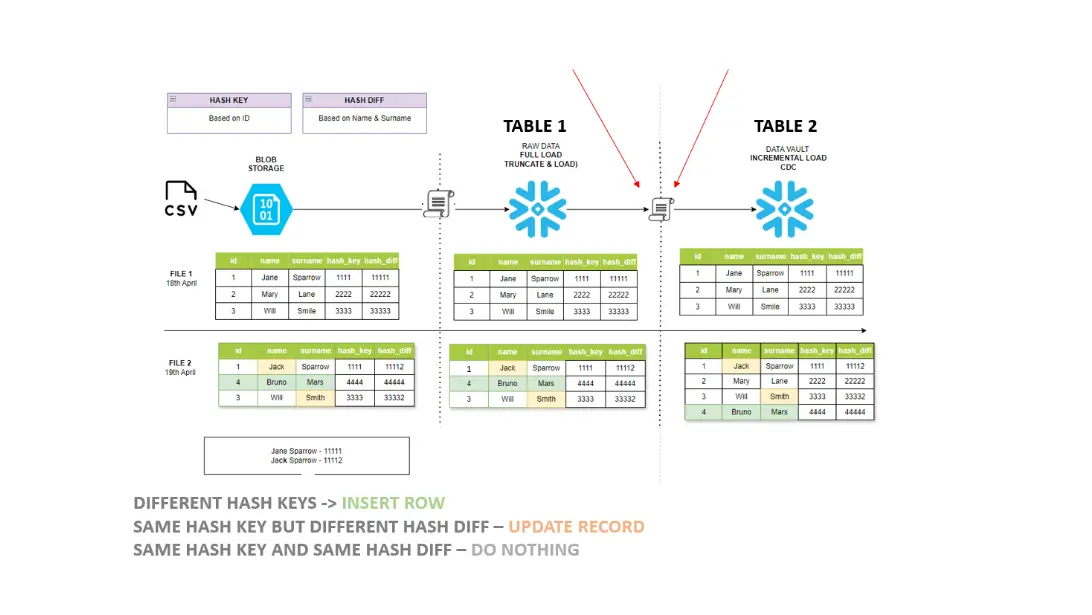
Check the example from the image and below the code and videos to recreate this example. Hashes are not real but just for illustrative purposes.
Material to create your tables + merge in Snowflake
---HASH KEY AND HASH DIFF USED IN TABLE 1_VIEW-------
CAST(SHA2_BINARY(NVL(CAST(id AS VARCHAR),'null') ) AS BINARY(40)) as hash_key,
CAST(SHA2_BINARY(NVL(CAST(name AS VARCHAR),'null') ||'||'|| NVL(CAST(lastname AS VARCHAR),'null') ) AS BINARY(40)) AS hash_diff
----FULL SETUP----
---CREATE TABLE 1 and load file 1---------------------------------------------------
CREATE TABLE customer (
id INT PRIMARY KEY,
name VARCHAR(50),
lastname VARCHAR(50)
);
INSERT INTO customer (id, name, lastname)
VALUES
(1, 'Jane', 'Sparrow'),
(2, 'Mary', 'Lane'),
(3, 'Will', 'Smile');
select * from INDATAWETRUST.PUBLIC.CUSTOMER;
---CREATE TABLE 1_VIEW------------------------------------------
CREATE VIEW customer_view AS
SELECT
id,
name,
lastname,
CAST(SHA2_BINARY(NVL(CAST(id AS VARCHAR),'null') ) AS BINARY(40)) as hash_key,
CAST(SHA2_BINARY(NVL(CAST(name AS VARCHAR),'null') ||'||'|| NVL(CAST(lastname AS VARCHAR),'null') ) AS BINARY(40)) AS hash_diff
FROM customer;
select * from customer_view;
---CREATE TABLE 2 AND MERGE FROM TABLE 1_VIEW TO TABLE 2---------------------------------------------
CREATE TABLE customer_hashed (
id INT PRIMARY KEY,
name VARCHAR(50),
lastname VARCHAR(50),
hash_key BINARY(40),
hash_diff BINARY(40)
);
MERGE INTO customer_hashed AS target
USING customer_view AS source
ON target.hash_key = source.hash_key
WHEN MATCHED AND target.hash_diff <> source.hash_diff THEN
UPDATE SET
name = source.name,
lastname = source.lastname
WHEN NOT MATCHED THEN
INSERT (id, name, lastname,hash_key,hash_diff)
VALUES (source.id, source.name, source.lastname, source.hash_key,source.hash_diff);
select * from INDATAWETRUST.PUBLIC.CUSTOMER_HASHED;
---TRUNCATE TABLE 1 AND LOAD 2nd file TO TABLE 1------------------------------------------
TRUNCATE TABLE customer;
INSERT INTO customer (id, name, lastname)
VALUES
(1, 'Jack', 'Sparrow'),
(4, 'Bruno', 'Mars'),
(3, 'Will', 'Smith');
---MERGE AGAIN FROM TABLE 1_VIEW TO TABLE 2------------------------------------------
MERGE INTO customer_hashed AS target
USING customer_view AS source
ON target.hash_key = source.hash_key
WHEN MATCHED AND target.hash_diff <> source.hash_diff THEN
UPDATE SET
target.name = source.name,
target.lastname = source.lastname
WHEN NOT MATCHED THEN
INSERT (id, name, lastname,hash_key,hash_diff)
VALUES (source.id, source.name, source.lastname, source.hash_key,source.hash_diff);
select * from customer_hashed;